(Part 2 in a series about Artificial Intelligence and New Zealand native birds.)
Inside a computer, 20 seconds of audio are represented by a sequence of 320,000 numbers.
 |
| 20 seconds of audio, plotted as a waveform |
- Birds nearby and birds far away increase the Index about the same.
- Background noises don't affect the Index very much.
- The Cacophony Index for two sparrows chirping should be higher than if there's only one.
- The Cacophony Index for a sparrow chirping and an owl hooting should be higher than for two sparrows chirping.
Wow, that’s a really hard thing to do! As happens often in this blog, we'll make the problem easier by adding in some assumptions:
"Perfect is the enemy of good" - Voltaire
Are we justified in making all these assumptions?
...Well, no...
Lets build something useful instead of freaking out that a perfect solution can't exist.
That means we're going to just ignore a whole bunch of nasty complications like “clipping”, “nyquist rate”, “attenuation”, “noise floor”, etc
Because PROGRESS!
Are we justified in making all these assumptions?
...Well, no...
...but...
... let's do it anyway.
Lets build something useful instead of freaking out that a perfect solution can't exist.
That means we're going to just ignore a whole bunch of nasty complications like “clipping”, “nyquist rate”, “attenuation”, “noise floor”, etc
Because PROGRESS!
- Most of the loud noises in the recordings are birds, not people or cars or machines.
- The recording is “clean”
- The birds and the recorder stay in the same place.
- No running water or ocean waves (!)
- The recording was taken in New Zealand (!!)
Great stuff! Lets look at the spectrogram:
 |
|
The spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time.
|
We don’t care so much about the intensity of any given bird call, that mostly tells us how near or far the bird is.
We don’t care so much if the bird has a short call or a long call.
Background noise? That’s where the spectrogram is well.. noisy..
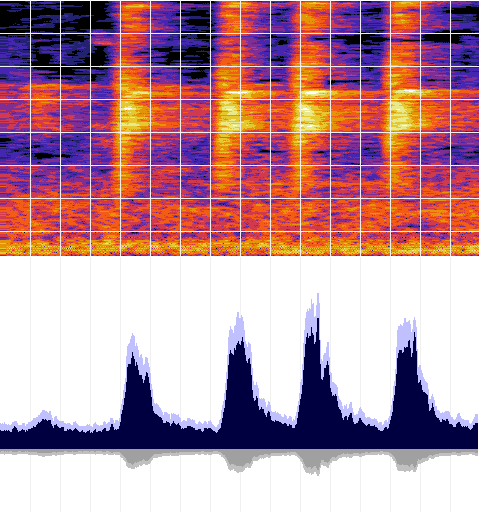 |
| Count the number of times a yellow box is next to a blue box! That's the heart of the Cacophony Index calculation. |
What we’re really looking for is how the spectrogram changes over time.
Lets zoom in on that starting second and add a grid to isolate the signal in both time and frequency:
A little bit more math and we find the cacophony index for this particular audio recording is: 77
OK, you got me, I'm oversimplifying again! ¯\_(ツ)\_/¯ If you want all the gory details, the code is on github.com
Lets talk Birds!
The Cacophony Index for 20 seconds of audio is just a number between zero and one hundred. By itself, not super useful.If we make many recordings in the same location, we can plot how the Cacophony Index changes over time. Here's one possible presentation of what that might look like over the course of a day:
 |
| You can clearly see the birds are more active during the day and less active during the night. The birds getting really noisy around sunrise and sunset, the "Dawn Chorus". |
Even though the plot is a mock-up, the data is real. It's data from a real bird monitor, recorded near Christchurch, New Zealand over a three week period in November of 2019. We now have the technology to see how the Cacophony Index changes over a day, or a week, or even seasons, years or decades.
And that's exactly what the Cacophony Project are doing, using real audio recorded right here in New Zealand, uploaded continuously and automatically by people just like you! (Edit: Live! Check it out!)
I think that's awesome. Can we go deeper?
Now we have an automated way to track an ecosystem's health, what else can we do with the audio data?
Watch this space for an update using real AI using Tensorflow and some real world ethical problems.









{kind=link}